Nvidia has developed a desktop super computer based on graphics processing units. I will keep my notes on the subject here.
This will probably be a good area for people to get in early. It is going to enable many things. There are currently probably not many people who have experience with these computational techniques.
GPU processing architecture
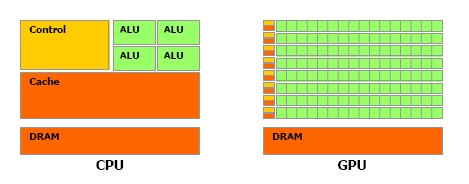
In a GPU more transistors are devoted towards processing than data caching and flow control. More specifically, the GPU is especially well-suited to address problems that can be expressed as data-parallel computations – the same program is executed on many data elements in parallel – with high arithmetic intensity – the ratio of arithmetic operations to memory operations. Because the same program is executed for each data element, there is a lower requirement for sophisticated flow control; and because it is executed on many data elements and has high arithmetic intensity, the memory access latency can be hidden with calculations instead of big data caches.
On page 57 of reference #1 an example matrix multiply is detailed with example code. Matrix multiplication is very important to many different types of simulations.
References
- NVIDIA CUDA Compute Unified Device Architecture
- Thread – A thread of execution is a fork of a program into two or more concurrently running tasks. The implementation of threads and processes differs from one operating system to another, but in general, a thread is contained inside a process and different threads in the same process share some resources (most commonly memory), while different processes do not.
0 Comments